Best practices in action: Cleaning up legacy code
Have you ever had that "f*** me" feeling when looking at some legacy code? I feel you, let's see how to tackle those mfs 💪

Have you ever had that f*** me feeling when looking at some legacy code you had to rescue? I feel you.
This week I found a great example I’ll try to refactor to make it more human-readable. Please follow me in this painful -but rewarding- journey.
The original code
This is the particular function I came across. It was originally included in the filter.service.js file from a dashboard web app, intended to handle user filters such as date ranges, etc.
Please take some time trying to figure out what it’s supposed to do.
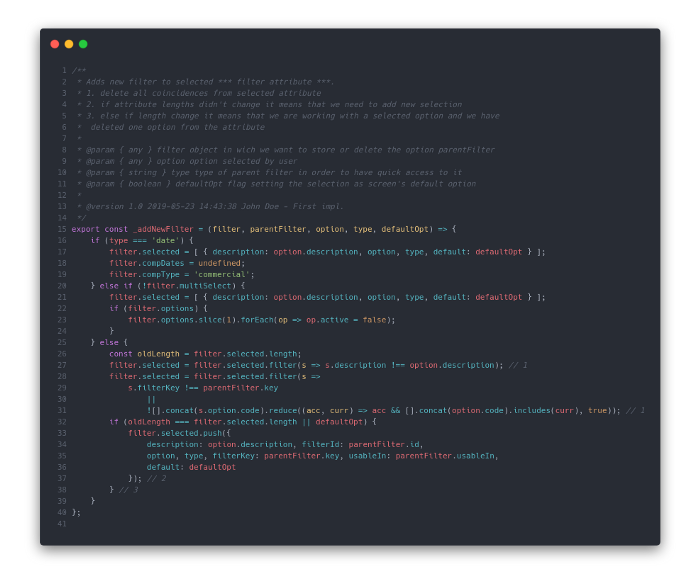
After a few minutes of reading it carefully, I assumed this function sets a filter option as selected, supporting many different filter types: date filter, single selection, and multiple selection filters.
Before starting
Before starting to make any changes, we should make sure they won’t break the app’s behaviour.
The only way to refactor code with all the guarantees is by having unit tests. They ensure our code works as expected after every change we’ll be doing.
If all the tests remain green, it means our function still behaves the same way: Red -> Green -> Refactor.
Comments
The header comment looks fine at first sight: it describes the function goal, its arguments, etc. However, this kind of comments have some important issues:
- It’s outdated: an outdated comment is even worse than no comments at all. In this case, the last parameter is not documented. Misleading comments should be removed.
- Change history: we’re already using git as CSV, there’s no need to maintain the change history with comments. It’s also outdated, as I said before this is the main issue with this kind of comment.
- Comments about flow: each if branch has a comment to identify which case is applying. This is a clear sign for a confusing structure, we wouldn’t need it otherwise.
Besides this is a private function, not a public API; so we don’t need any js-doc since anyone will be using them.
Comments are helpful when they explain design decisions -why-. But when they’re used to clarify an implementation -how- they’re a definite sign that our code is a mess.
Proper naming
Following the precious advice, most comments could be omitted with proper naming.
Naming is hard, but also very important.
This function name caught my attention. It looks like _addNewFilter would add a new filter to the dashboard, but it doesn’t since all the filters are available from the start. It’s actually setting an option as active for a filter. Considering this, it makes sense to change its name for _selectFilterOption, which is more expressive.
Duplication
Looking at the code we see some duplicated statements, like variable declarations or object structures.
The more duplicated code we have, more difficult any change is. Bug are also more likely to appear.
In this example, we’re declaring selectedOption once and use it afterward when needed.
Pure functions
This function modifies the arguments, which are passed by reference since they’re non-primitive types in JavaScript.
These side-effects force us to know what the function actually does and expect passed objects to be modified. This is a terrible smell.
We should always use pure functions instead. Pure functions receive an argument a return an output value. Avoiding side-effects is usually an effective way to avoid bugs.
Function arguments
Using fewer arguments as possible is another recommendation.
Functions with many -more than 2- arguments are likely to disregard the Single Responsibility Principle. Functions should always do one single thing.
Besides, selector arguments like defaultOpt are another hint of multiple behaviours within a function.
We’ll make default and type filter attributes, since it makes sense and saves us two arguments from our function’s signature.
This is how the code looks so far:
Structure
Since this function is doing several things, it should be broken down in smaller code blocks.
Functions must be small, expressive and do one single thing.
Let’s handle the logic in the main function, and then each case with behavior-specific functions:
Complexity
The complexity of these statements is absolutely overwhelming, both in conditionals and filters:
It’s concatenating an empty array with a single value, to check then if it’s present in the array… Which is the same than a straight comparison:
Besides conditionals have multiple operators and a high level of indentation. This could be simplified by using different functions, as we’ll see later.
Rule of thumb is declaring conditionals in properly named variables, so we can just read conditions up.
Also, negatives should be avoided in favor of affirmative conditions, because they’re much more natural to read.
Order
Code should be written left to right, and top to bottom. Exactly the same as any other text, so functions are declared as we need them.
In the final result, we can check how code is declared as we use it.
Final result
Does this solution have more lines of code? Yes. Is it easier to understand? Definitely. Just compare how long did it take you to understand the original one, comparing to this last alternative.
If you arrive fresh at this team, which option would you like to find?
How long would you take to modify the first function to handle another type of filter? And the second one?
Conclusion
This was just one example, but refactoring must be part of your workflow, instead of an eventual cleaning task. Every time you find poorly written code, just clean it up! Just be a good boy scout.
Our professional duty is not just to make things work but make them PROPERLY. Code rottens as it evolves.
Besides, the only way to refactor anything with guarantees is by having unit tests. They’re the key to everything.